Beyond the Stars Improving Rating Predictions Using Review Text Content
ane. Introduction
The rapid development of Web 2.0 and e-commerce has led to a proliferation in the number of online user reviews. Online reviews contain a wealth of sentiment information that is important for many decision-making processes, such as personal consumption decisions, commodity quality monitoring, and social opinion mining. Mining the sentiment and opinions that are contained in online reviews has go an important topic in natural language processing, machine learning, and Web mining.
The sentiment classification of online reviews is the most fundamental and of import work in natural language processing [1,2]. At nowadays, the review sentiment nomenclature (positive and negative) has been widely studied, only the review sentiment classification cannot meet the demand for fine-grained review sentiment assay [three,4,5,6,7]. For example, how do consumers choose the most advisable product from several products that are existence reviewed? Horrigand's research shows that consumers are willing to pay an actress xx% to 99% to buy a five-star rated production instead of a four-star rated one [eight]. This shows that the nuances of production ratings tin lead to dramatic changes in product sales. In public opinion monitoring, the government not only wants to understand the positive and negative sentiment categories of the reviews, only as well wants to farther sympathise the positive and negative sentiment intensity to distinguish the urgency of public opinion events and have different measures. As a result, researchers are paying more and more attention to review rating predictions (RRP).
Existing RRP methods are mainly based on the review content. From the perspective of natural language processing, the review content is converted into a text feature vector, then a linear regression model is used to model the RRP [ix,x,xi,12,thirteen]. For example, Qu et al. regarded the RRP equally a feature applied science problem, and improved the operation of RRP by extracting different features, such every bit words, lexical patterns, syntactic structures, and semantic topics from the review content [10]. Zhang et al. used deep CNN on word embedding to learn the features of reviews, which are then fed into a softmax layer to obtain sentiment predictions [xiii].
Existing RRP methods that are based on review content accept an implicit hypothesis: the sentiment polarity and intensity expressed by the aforementioned sentiment words is consistent, and the sentiment polarity and intensity expressed by dissimilar sentiment words is dissimilar. Even so, this implicit assumption does not concord in the actual scenario. For example, a demanding user gave a five-signal rating to the Huawei mobile phone with the sentiment word "practiced", while another tolerant user might give a four-star rating with the aforementioned sentiment word "good". Different users use same sentiment words to express dissimilar sentiment intensity, which reflects the user context of sentiment discussion is very important to RRP. For another example, the sentiment word "simple" in the review "this movie is uncomplicated" expresses negative sentiment. While in the review "this phone is simple to utilize", it expresses positive sentiment. For different products, the same sentiment words are used to express different sentiment polarities, which reflect the product context of sentiment word has a certain impact on RRP. Through the to a higher place assay, information technology tin be institute that RRP is not only related to the review text content, but is also related to the user context data and the product context information.
Some studies take shown that user context information is an of import data source for online review rating prediction [14,15,16,17]. Wang et al. believe that the rating is non entirely determined by the review content, because a enervating user may comment on all products with harsh words, even if he gives a very high rating to the product [14]. Some researchers believe that product context data is another important information source for online review rating prediction. Tang et al. believe that a product has a collection of product-specific words suited to evaluate it [15]. For example, people prefer using "sleek" and "stable" to evaluate a smartphone, while like to utilize "wireless" and "mechanical" to evaluate a keyboard. Wu et al. believe that the same words may have unlike or even opposite sentiment meanings in the reviews of different products [16]. For example, "easy" is a positive sentiment in "this digital camera is like shooting fish in a barrel to use", however, information technology may take a negative sentiment meaning in "the ending of this movie is easy to guess".
The main problem with the existing RRP methods that are based on review content is that the user context dependency and production context dependency of the sentiment word cannot be processed very well based merely on the review content information. So, we propose a review rating prediction method based on user context and product context (RRP + UC + PC). Our method firstly models the user context dependency of sentiment word, and it proposes a review rating prediction method that combines the review content and the user context. Then, the product context dependency of sentiment words is modeled, and a review rating prediction method based on review content and product context is proposed. Finally, a review rating prediction method that is based on user context and product context is proposed.
The main contributions of this paper can be summarized every bit:
- (ane)
-
We propose a review rating prediction method based on user context and product context.
- (two)
-
Aiming at the trouble of user context dependency of sentiment words, a review rating the prediction method based on review content and user context is proposed. Aiming at the trouble of product context dependency of sentiment words, we proposed a review rating prediction method based on review content and product context.
- (3)
-
We conduct comprehensive experiments on four large-calibration datasets for RRP. We find that our methods significantly outperform the state-of-the-fine art baselines.
The residuum of this paper is organized every bit follows: we describe the related works in Section ii. Our methods are described in Section 3. In Section 4, we draw experimental setup and discuss the operation evaluation results. Section 5 concludes the paper and it outlines time to come inquiry directions.
2. Related Piece of work
2.1. RRP Based on Review Content
Existing RRP methods mostly focused on review content to mine the sentiment information [ten,18,nineteen,20]. Pang and Lee proposed and studied the RRP problem (the score is generally divided into i to 5 points) [eighteen]. Since the ratings have a certain gild, the RRP are by and large formatted as regression problems. Pang and Lee used SVM regression model and SVM multi-classifier (i-to-many strategy), respectively, for sentiment prediction. The experimental results show that SVM regression model shows ameliorate performance than SVM multi-classifier in RRP. Because the numerical score is not a classification aspect value, the classification model is not equally effective equally the regression model.
Qu et al. proposed a bag-of-opinions review text representation model that is different from the traditional bag-of-words text representation model, and and then obtained the sentiment phrases through the bag-of-opinions review text representation model [10]. Each viewpoint is represented equally a triple, which is a sentiment word, a modifier, and a negative word (such every bit in "not very good", "good" is a sentiment word, "very" is a modifier, and "not" is negative give-and-take). For the sentiment classification that just requires positive and negative tendencies, the modifier does not play a key role, only in RRP, both the modifier and the negative word play an of import part. In a labeled domain-contained corpus (from multiple domains), a constrained ridge regression model is firstly used to larn each viewpoint feature (sentiment intensity and score), and then extend the traditional unigrams characteristic through viewpoint features to achieve RRP.
There are also some researches based on review content that have into account the reviewers and items information [14,19]. Wang et al. believe that the rating is not entirely adamant by the review content, considering a tolerant user may comment on all items with positive words, even if he requite a lower rating to the item [14]. Following the work of [14], a method of incorporating user and item into review content is proposed in [19]. Li et al. takes into business relationship the data of user and item when mining the review content, and uses tensor factorization to learn the parameters of the regression model and achieve RRP.
2.2. Missing Rating Prediction in User-Item Rating Matrix
A study that is relevant to RRP is the missing rating prediction for the user-item rating matrix in the recommendation system. The departure between RRP and the missing rating prediction in the user-particular rating matrix is that the RRP is based on the review data published by the user to predict the review rating; and the missing rating prediction in the user-detail rating matrix is based on history rating that is written by users in the user-item rating matrix to predict the missing rating. Ii different types of rating prediction studies are used to accomplish rating prediction from unlike perspectives. Therefore, the prediction method of missing rating in the user-item rating matrix has important reference significance for RRP.
The missing rating prediction methods for the user-item rating matrix in the recommendation organization mainly include: K-nearest neighbor (KNN) and matrix factorization (MF). KNN-based rating prediction mainly includes a method that is based on user similarity and method based on particular similarity [21,22]. The primal idea of KNN-based method is to summate the similarity between users based on the user-item rating matrix information, and then predict the target user's missing rating on the item past the history rating of the K users with the highest similarity to the target user. The idea of KNN-based method is similar to that while using the user similarity method, except that the user is replaced by an item. The key idea of MF is to project users and items into a shared latent cistron space, and then models interactions between users and items with the inner item of latent factor vectors of users and items [23,24].
2.three. Review-Based Recommendation
When the user-item rating matrix is sparse, the recommendation performance will be significantly reduced. Therefore, some enquiry work considers review content information to improve missing rating predictions in user-item rating matrix. The effectiveness of using review content information in the recommendation has been extensively discussed and demonstrated in many existing studies [13,25,26,27].
While because user review content information, some research works generate latent factors for users and items by integrating topic models in the collaborative filtering framework [28,29,thirty,31,32,33]. Ane of the early studies of using review content to improve missing rating predictions in a user-item rating matrix was proposed in [34]. This work found that reviews often include information, such as cost, service, positive, or negative sentiments that can be used for missing rating predictions in use-item rating matrix. Subconscious factors as topics were proposed to discover potential aspects from item or user reviews using topic model in [30]. This approach achieved significant improvements over models that but use user-detail ratings matrix or review content.
Existing review-based recommendation methods predict the missing ratings in the user-detail rating matrix from the history of review texts written by a user. While in our newspaper, we mainly written report the rating prediction of an existing review. Existing review-based recommendation methods provide a common RRP recommendation model for all the users. In contrast, our approach builds a user-specific and product-specific review rating prediction model for each user and each product.
3. RRP Based on User Context and Product Context
3.ane. Problem Clarification
Suppose there is an online review site that contains Due north items and M users. The M users have published T reviews and respective ratings on N items. Our goal is how to finer predict the rating of reviews by using review content information. That is, nosotros want to discover a role f: input of the role f is review content; the output of the function f is review rating.
3.two. RRP Method Based on Review Content and User Context
The review content is the most important source of information for RRP. The existing RRP methods that are based on review content mainly utilize a vector space model to represent the review content, and and then implement RRP through a linear regression model. Specifically, user u has posted a review r ui on the item i. The existing RRP office based on the review content is as followed:
Here,
is the predicted rating of user u for item i; w is the parameters of the function; and, r ui is the vector representation of review content.
Due to the differences in sentiment expression of unlike users in online social media, the general RRP model built for all users cannot accurately understand the special sentiment expression of each user. It is the most intuitive method to pattern a personalized RRP method for each user past using the personal review content published by each user in the online social media. Still, in online social media, the personal review data published past a single user is usually very express. Therefore, based on the personal review data lone, it is impossible to accurately railroad train a RRP model for each user.
Psychology and sociology studies have shown that, although online users express their sentiments in a personalized fashion, dissimilar online users share many of the same sentiment expressions [35]. For case, "happy" and "good" are oftentimes used to express the positive sentiment among different users. Therefore, making total use of the shared sentiment data between unlike users tin can help to solve the trouble of bereft data for a single user.
Based on the above analysis, we suggest a RRP model that is based on the review content and user context. In social club to model the sentiment commonality of different users and sentiment personality of private user, the RRP model is decomposed into two components, a mutual one and a user-specific one. The mutual part is shared past all users to characterize the sentiment information shared by different users and to use all user data for preparation. The user-specific role is unique to each user and information technology is used to characterize each user's specific sentiment expression and to apply a single user's information for learning.
Specifically, user u has posted a review r ui on the item i. The RRP model based on the review content and user context is every bit followed:
Hither,
is the predicted rating of user u for detail i; w and w u are the mutual and user-specific parameters in RRP model; and, r ui is the vector representation of review content.
To calculate the parameter vector w and w u , given the training data ready and, we apply the least squares error loss principle to minimize the objective office in preparation data fix.
Here,
is the regular coefficient, ||w|| and ||westward u || are the regular term of the parameter vector due west and w u . To estimate the parameter vector due west and w u , we use a stochastic gradient descent algorithm to solve this optimization problem. Nosotros use the following update rules to learn the parameters w and w u .
Here,
, η is learning rate. After getting w and w u , given reviews in examination datasets, we tin use
to predict the review rating.
3.3. RRP Based on Review Content and Production Context
Due to the differences in sentiment expression of different products in reviews, the general RRP model that is built for all products cannot accurately understand the special sentiment expression of each product. It is the most intuitive method to design a personalized RRP method for each product by using the personal review content published for each production. However, the personal review data published for a single product is usually very express. Therefore, based on the personal review data solitary, it is incommunicable to accurately train a RRP model for each product.
Although each product has its own unique sentiment expression, unlike products have many identical sentiment expressions. For example, general sentiment words such every bit "perfect", "fantabulous", and "bad" often limited a constant sentiment tendency in dissimilar products. Therefore, making full apply of the shared sentiment information between unlike products can help to solve the problem of insufficient information for a single product.
Based on the in a higher place analysis, we propose a RRP model based on the review content and product context. In club to model the sentiment commonality of dissimilar products and sentiment specific of individual production, the RRP model is decomposed into ii components, a common i and a product-specific one. The mutual function is shared by all products to characterize the sentiment data shared by dissimilar products and to employ all product information for training. The production-specific part is unique to each product and it is used to narrate each product-specific sentiment expression and to use a single product'south data for learning.
Specifically, user u has posted a review r ui on the item i. The RRP model that is based on the review content and product context is as followed:
Hither,
is the predicted rating of user u for detail i; w and w i are the mutual and product-specific parameters in RRP model; and, r ui is the vector representation of review content.
To calculate the parameter vector w and w i , given the training data set and, we employ the least squares error loss principle to minimize the objective function in preparation data ready.
Here,
is the regular coefficient, ||w|| and ||west i || are the regular term of the parameter vector w and w i . To estimate the parameter vector w and w i , nosotros use a stochastic gradient descent algorithm to solve this optimization problem. We use the post-obit update rules to learn the parameters w and due west i .
Here,
, η is learning rate. Afterward getting w and westward i , given reviews in examination datasets, nosotros can apply
to predict the review rating.
3.4. RRP Based on User Context and Production Context
In Section three.1, nosotros present our research goals through a toy example. In Section 3.2, we present a RRP model based on the review content and user context. In Department 3.three, we present a RRP model that is based on the review content and product context. In this part, we propose a RRP method based on user context and production context by integrating the user context information and the product context information.
Here,
is the predicted rating of user u for item i; west, w u , westward i are the common, user-specific and production-specific parameters in RRP model; and, r ui is the vector representation of review content.
In order to get optimum parameters westward, w u , w i , given training datasets available, nosotros use the least square fault loss principle to minimize the objective function.
Here,
is the regular coefficient, ||w||, ||due west u ||, and ||w i || are the regular term of the parameter. To estimate the parameter westward, due west u , and w i , we use a stochastic gradient descent algorithm to solve this optimization problem. We use the post-obit update rules to larn the parameters w, w u , and w i .
Here,
, η is learning charge per unit. After getting w, w u , and west i , given reviews in examination datasets, we tin can use
to predict the review rating.
four. Experiments and Evaluations
We have performed extensive experiments on a variety of datasets to demonstrate the effectiveness of our methods when compared to other land-of-the-fine art RRP method. We first introduce the datasets and the evaluation metric used in our experiments in Section 4.one. Experimental settings and research trouble are given in Section four.2. Performance evaluation and some analysis of the model are discussed in Section iv.3, Department 4.4 and Section four.five, respectively.
four.one. Datasets and Evaluation Metric
In order to evaluate the performance of our methods, we respectively implement our experiments on English data sets and Chinese information sets. We have selected two public English data sets Yelp 2013 and Yelp 2014, which is a large-scale dataset consisting of restaurant reviews (https://world wide web.yelp.com/dataset/challenge). On the Chinese dataset, nosotros synthetic 2 Douban motion picture review datasets considering there is no suitable public dataset in Chinese.
Douban (http://www.douban.com/) is a popular Chinese review site where users tin can post comments on movies, books and music and give a 1 to 5 star rating. Through the API interface that is provided by Douban, we download the Douban movie user data and so sort the Douban motion-picture show users co-ordinate to the number of published reviews. We selected picture show users who have published more than 50 movie reviews every bit seeds. Focusing on the flick users, through the Douban API interface, grab the movie reviews published by Douban flick users. Based on the captured Douban data, two movie review information sets were synthetic. The statistics of the four datasets are shown in Table 1.
Nosotros use mean absolute error (MAE) and root mean square error (RMSE) equally evaluation indicators to evaluate the performance of dissimilar RRP methods. MAE and RMSE are defined, as follows:
Here,
is the review rating predicted by diverse methods, fiveui is the true rating of the review in the test set, and N total is the number of reviews in the test set.
4.2. Experimental Settings and Research Questions
Nosotros divided each dataset shown in Table 1 into ii parts: training set and examination gear up. We use fourscore% of each dataset as the training gear up and the rest is used as the examination gear up. All of the hyper-parameters of our methods are selected based on the performance on the training set. For comparison, nosotros summarize our proposed models and baseline methods as follows.
-
LR + global: RRP method based on linear regression trained and tested on all users and products.
-
LR + global + UPF: Nosotros extract user features [36] and corresponding product features (denoted as UPF) from preparation data, and concatenate them with the features in baseline LR + global.
-
LR + private + production: RRP method based on linear regression trained and tested on private product.
-
LR + individual + user: RRP method based on linear regression trained and tested on private user.
-
KNN: RRP method based on k-nearest neighbor.
-
MF: RRP method based on matrix factorization.
-
RRP + UC: RRP method based on review content and user context.
-
RRP + PC: RRP method based on review content and product context.
-
RRP + UC + PC: RRP method based on user context and product context.
By combining the review content, user context and product context data, we suggest a RRP method based on user context and production context. To analyze the functioning of our method and the factors that touch the operation of our method, on the 4 datasets, we did three experiments to respond the following iii questions:
- (ane)
-
Whether our method operation is better than the criterion method.
- (2)
-
The impact of the number of reviews per user and reviews for each product on our methods
- (three)
-
The impact of user context and product context on our methods.
4.iii. Functioning Comparison of Different Methods
To verify the operation of our method, we compared our method and vi criterion methods on four unlike datasets. The RRP results of nine unlike methods are shown in Table ii.
On 4 different datasets, our approach reduced the MAE and RMSE of the RRP and accomplished better performance than the six criterion methods. Both the RMSE of global methods, such equally LR + global and LR + global + UPF, and those of individual methods, such as LR + individual + user and LR + individual + product, are college than our method. This is because the global methods neglect to capture the individuality of each user and production, and the private methods suffer from data sparseness. Our approach can outperform both the global and private methods because our method can capture individuality of user and product, and at the aforementioned fourth dimension, exploit the common cognition shared by different users and products to handle data sparseness problem.
In improver, our approach performs better than the KNN and MF method. It indicates that our method is a more advisable mode to RRP than KNN and MF. For example, the RMSE of RRP + UC + PC is reduced by 5.71% ((1.0387 − 0.9794)/1.0387) when compared to MF, which is the best method in baselines in Douban2. The RMSE of RRP + UC + PC is reduced by 7.47% ((0.8042 − 0.7441)/0.8042) compared to MF, which is the all-time method in baselines in Yelp 2013.
The experimental results prove that RRP + UC + PC can better the performance of the RRP. This is because RRP is not but related to the review text content, but besides related to user context and production context. By combining the user context and product context information, the performance of the RRP is improved to some extent.
From Tabular array 2, we can discover a very interesting result. In douban1 and douban2 datasets, the MAE of RRP + UC + PC is only reduced by 4.32% ((0.8477 − 0.8111)/0.8477) and 5.73% ((0.8277 − 0.7803)/0.8277) every bit compared to LR. However, in yelp2014 and yelp2013 datasets, the MAE of RRP + UC + PC is reduced by 14.86% ((0.5686 − 0.4841)/0.5686) and 17.27% ((0.5623 − 0.4652)/0.5623) compared to LR. This is because the number of reviews per user and reviews for each production in yelp datasets are much larger than the number of reviews per user and reviews for each product in the douban datasets.
4.four. The Touch on of the Number of Reviews Per User and Reviews for Each Product on Our Methods
In club to further enquiry the impact of the number of reviews per user and reviews for each product on our methods. We hope to reply two questions through experiments. First, increasing the number of reviews per user tin benefit each user's personalized RRP. Second, increasing the number of reviews per product can benefit the personalized RRP for each product.
To written report the impact of number of reviews per user on our proposed arroyo, in the experiment, we selected P% reviews for each user to railroad train RRP + UC. The value of P varies from 10 to 100 at intervals of 10. The experimental results on the yelp2013 datasets are shown in Figure 1. The results of the RRP + LR + individual + user and RRP + LR + global methods are besides shown in Effigy 1 as a baseline method for comparison.
From Figure 1, we can see that, as the number of reviews per user increases, the MAE of our proposed method and baseline methods are decreasing. This result is because as the number of reviews per user increases, more information is used in the grooming process of RRP, thus helping to learn a more accurate RRP method. In improver, the effects of our method proposed in this paper can be better than the LR + private + user and LR + global methods in different preparation text sizes. This is because the LR + global arroyo does not capture the personalized sentiment expression of each user, while the LR + individual + user approach faces the challenge of data sparsity. In addition, the functioning of our proposed method becomes more apparent than the LR + individual method when the number of grooming texts per user is reduced.
Even so, compared with the LR + global method, our method fluctuates more with the change of the number of reviews per user. Our method is more than sensitive to the preparation data than, and not as stable as, the LR + global method.
To study the bear on of reviews for each production on our proposed arroyo, in the experiment, we selected P% reviews for each product to train RRP + PC. The value of P varies from 10 to 100 at intervals of x. The experimental results on the yelp2013 datasets are shown in Figure ii. The results of the LR + private + product and LR + global methods are too shown in Figure 2 equally a baseline method for comparison. From Effigy 2, we tin become a conclusion like to Figure 1.
4.5. The Impact of User Context and Production Context on Our Methods
To evaluate the touch of user context and production context on RRP, we separately remove user context and production context from RRP + UC + PC and conducted comparative experiments on four datasets. The experimental results of the 4 datasets are shown in Figure 3 and Figure 4, respectively.
From Figure 3, nosotros can find the MAE of RRP + UC + PC is profoundly improved when the user context data is removed compared to the removal of the product context. For example, when the user context information is removed, the MAE of RRP + UC + PC is increased by 4.49% ((0.8170 − 0.7803)/0.8170) in the douban2 datasets. Yet, when the product context information is removed, the MAE of RRP + UC + PC is simply increased by 3.44% ((0.8081 − 0.7803)/0.8081) in the douban2 datasets.
From Figure 4, nosotros tin can get the aforementioned result. Nosotros find the RMSE of RRP + UC + PC is profoundly improved when the user context information is removed every bit compared to the removal of the production context. For example, when the user context information is removed, the MAE of RRP + UC + PC is increased by 8.29% ((0.8114 − 0.7441)/0.8114) in the yelp 2013 datasets. However, when the product context information is removed, the MAE of RRP + UC + PC is only increased by 7.27% ((0.8024 − 0.7441)/0.8024) in yelp2013 datasets.
The experimental results on four different datasets evidence that user contexts are more constructive than product contexts in RRP. This is because the user context information contains non just user-special words, but too user's personal sentiment bias.
5. Conclusions
In this paper, we present a new RRP method that is based on the user context and product context. More specifically, in society to solve problem of existing RRP methods based on review content, considering the user personalized information and product context information, which are useful to predict rating of review, nosotros propose a RRP method based user context and product context. Experimental results on four datasets show that our proposed methods accept more than operation than the state-of-the-art baselines in RRP.
Existing review rating prediction methods only use a unmarried model to capture the sentiment of review texts. Our method respectively considers affection of user and product on reviews content in capturing the sentiment of review texts. Even so, our method does non regarding mutual amore of user and product on review texts in capturing the sentiment of review texts. Regardless of existing methods or our method, but the review content data is modelled in RRP. In the future, in order to address these issues, nosotros volition firstly model together affection of user context and product context on reviews texts, incorporating the user-product-specific model into our method to further ameliorate the performance of RRP. At the same time, we will use user and product context information as the attending mechanism of the neural network model to conform the weighting coefficient of the global model, user-specific model, product-specific model, and user-product-specific model in our proposed futurity method.
Author Contributions
Conceptualization, B.W.; Data curation, Y.H.; Formal analysis, B.W.; Investigation, B.W.; Methodology, B.West.; Project administration, Y.H.; Supervision, X.L.; Writing—original draft, B.W.; Writing—review & editing, 10.Fifty.
Funding
This research was funded by Foundation of He'nan Educational Committee (19A520032) and Ph.D. Offset-upwards Foundation of Pingdingshan University (PXY-BSQD-2018007) and National Natural Science Foundation of China (U1536201, U1405254, and 61271392).
Acknowledgments
Thanks to Zhigang Yuan for valuable discussions on the research and the manuscript.
Conflicts of Interest
The authors declare no conflict of involvement.
References
- Pang, B.; Lee, Fifty. Opinion mining and sentiment analysis. Found. Trends Inf. Retr. 2008, 2, 1–135. [Google Scholar] [CrossRef]
- Liu, B. Sentiment analysis and opinion mining. Synth. Lect. Hum. Lang. Technol. 2012, v, i–167. [Google Scholar] [CrossRef]
- Khan, F.H.; Qamar, U.; Bashir, S. A semi-supervised approach to sentiment assay using revised sentiment strength based on Senti Word Net. Knowl. Inf. Syst. 2017, 51, 851–872. [Google Scholar] [CrossRef]
- Khan, F.H.; Qamar, U.; Bashir, S. e SAP: A conclusion support framework for enhanced sentiment assay and polarity classification. Inf. Sci. 2016, 367, 862–873. [Google Scholar] [CrossRef]
- Khan, F.H.; Qamar, U.; Bashir, S. Multi-objective model selection (MOMS)-based semi-supervised framework for sentiment analysis. Cogn. Comput. 2016, viii, 614–628. [Google Scholar] [CrossRef]
- Khan, F.H.; Qamar, U.; Bashir, S. SWIMS: Semi-supervised subjective feature weighting and intelligent model selection for sentiment analysis. Knowl. Based Syst. 2016, 100, 97–111. [Google Scholar] [CrossRef]
- Mishra, S.; Diesner, J.; Byrne, J.; Surbeck, East. Sentiment analysis with incremental human-in-the-loop learning and lexical resources customization. In Proceedings of the 26th ACM Conference on Hypertext & Social Media, Guzelyurt, Cyprus, i–iv September 2015; pp. 323–325. [Google Scholar]
- Horrigan, J. Online Shopping; Pew Internet and American Life Project Report; Pew Enquiry Middle: Washington, DC, U.s., 2008. [Google Scholar]
- Wu, Y.; Ester, 1000. FLAME: A probabilistic model combining aspect based opinion mining and collaborative filtering. In Proceedings of the Eighth ACM International Conference on Spider web Search and Data Mining, Shanghai, China, 2–6 February 2015; pp. 199–208. [Google Scholar]
- Qu, 50.; Ifrim, G.; Weikum, M. The pocketbook-of-opinions method for review rating prediction from sparse text patterns. In Proceedings of the 23rd International Conference on Computational Linguistics, Beijing, China, 23–27 Baronial 2010; pp. 913–921. [Google Scholar]
- Zheng, L.; Zhu, F.; Mohammed, A. Attribute and Global Boosting: A Rating Prediction Method in Context-Aware Recommendation. Comput. J. 2018, lx, 957–968. [Google Scholar] [CrossRef]
- Ganu, Grand.; Elhadad, North.; Marian, A. Beyond the Stars: Improving Rating Predictions using Review Text Content. In Proceedings of the International Workshop on the Web and Databases, WEBDB 2009, Providence, RI, Us, 28 June 2009. [Google Scholar]
- Zheng, Fifty.; Noroozi, V.; Yu, P.S. Joint Deep Modeling of Users and Items Using Reviews for Recommendation. In Proceedings of the Tenth ACM International Conference on Web Search and Data Mining, Cambridge, UK, six–10 February 2017; pp. 425–434. [Google Scholar]
- Wang, H.; Lu, Y.; Zhai, C. Latent attribute rating analysis on review text data: A rating regression approach. In Proceedings of the 16th ACM SIGKDD International Conference on Noesis Discovery and Data Mining, Washington, DC, The states, 25–28 July 2010; pp. 783–792. [Google Scholar]
- Tang, D.; Qin, B.; Liu, T. Learning Semantic Representations of Users and Products for Certificate Level Sentiment Classification. In Proceedings of the 53rd Annual Meeting of the Clan for Computational Linguistics and the seventh International Joint Briefing on Natural language Processing, Beijing, China, 26–31 July 2015; pp. 1014–1023. [Google Scholar]
- Wu, F.; Huang, Y. Personalized Microblog Sentiment Nomenclature via Multi-Job Learning. In Proceedings of the Thirtieth AAAI Conference on Bogus Intelligence (AAAI'16), Phoenix, AZ, Us, 12–17 Feb 2016; pp. 3059–3065. [Google Scholar]
- Tang, D.; Qin, B.; Yang, Y.; Liu, T. User Modeling with Neural Network for Review Rating Prediction. In Proceedings of the Xx-Fourth International Joint Conference on Artificial Intelligence (IJCAI 2015), Buenos Aires, Argentine republic, 25–31 July 2015; pp. 1340–1346. [Google Scholar]
- Pang, B.; Lee, L. Seeing stars: Exploiting course relationships for sentiment categorization with respect to rating scales. In Proceedings of the 43rd Annual Meeting on Association for Computational Linguistics, Ann Arbor, MI, USA, 25–xxx June 2005; pp. 115–124. [Google Scholar]
- Li, F.; Liu, North.; Jin, H.; Zhao, K.; Yang, Q.; Zhu, X. Incorporating reviewer and production information for review rating prediction. In Proceedings of the Twenty-Second International Joint Conference on Artificial Intelligence, Barcelona, Espana, 16–22 July 2011; pp. 1820–1825. [Google Scholar]
- Liu, J.; Seneff, S. Review sentiment scoring via a parse-and-paraphrase paradigm. In Proceedings of the 2009 Conference on Empirical Methods in Natural Language Processing: Volume 1, Singapore, half-dozen–vii Baronial 2009; pp. 161–169. [Google Scholar]
- Lee, H.C.; Lee, S.J.; Chung, Y.J. A study on the improved collaborative filtering algorithm for recommender system. In Proceedings of the 5th ACIS International Conference on Software Engineering Research, Direction &Applications (SERA 2007), Busan, Korea, 20–22 Baronial 2007; pp. 297–304. [Google Scholar]
- Jeong, B.; Lee, J.; Cho, H. Improving memory-based collaborative filtering via similarity updating and prediction modulation. Inf. Sci. 2010, 180, 602–612. [Google Scholar] [CrossRef]
- Shi, Y.; Larson, Thousand.; Hanjalic, A. Collaborative filtering beyond the user-item matrix: A survey of the country of the art and time to come challenges. ACM Comput. Surv. 2014, 47. [Google Scholar] [CrossRef]
- Li, P.; Wang, Z.; Ren, Z.; Bing, L.; Lam, W. Neural rating regression with abstractive tips generation for recommendation. In Proceedings of the 40th International ACM SIGIR conference on Inquiry and Development in Data Retrieval, Shinjuku, Tokyo, Japan, vii–xi August 2017; pp. 345–354. [Google Scholar]
- Catherine, R.; Cohen, West. TransNets: Learning to Transform for Recommendation. In Proceedings of the Eleventh ACM Conference on Recommender Systems, Como, Italy, 27–31 August 2017; pp. 288–296. [Google Scholar]
- Kim, D.; Park, C.; Oh, J.; Lee, Southward.; Yu, H. Convolutional Matrix Factorization for Document Context-Aware Recommendation. In Proceedings of the 10th ACM Conference on Recommender Systems, Boston, MA, USA, 15–19 September 2016; pp. 233–240. [Google Scholar]
- Seo, S.; Huang, J.; Yang, H.; Liu, Y. Interpretable Convolutional Neural Networks with Dual Local and Global Attending for Review Rating Prediction. In Proceedings of the Eleventh ACM Conference on Recommender Systems, Como, Italia, 27–31 August 2017; pp. 297–305. [Google Scholar]
- He, X.; Chen, T.; Kan, M.; Chen, Ten. TriRank: Review-aware explainable recommendation past modeling aspects. In Proceedings of the 24th ACM International on Conference on Information and Knowledge Management, Melbourne, Australia, 18–23 October 2015; pp. 1661–1670. [Google Scholar]
- Ling, Grand.; Lyu, Yard.R.; King, I. Ratings run into reviews, a combined approach to recommend. In Proceedings of the 8th ACM Conference on Recommender Systems, Foster City, CA, U.s., 6–ten October 2014; pp. 105–112. [Google Scholar]
- McAuley, J.; Leskovec, J. Hidden factors and hidden topics: Understanding rating dimensions with review text. In Proceedings of the 7th ACM conference on Recommender Systems, Hong Kong, China, 12–xvi October 2013; pp. 165–172. [Google Scholar]
- Ren, Z.; Liang, South.; Li, P.; Wang, South.; de Rijke, One thousand. Social Collaborative Viewpoint Regression with Explainable Recommendations. In Proceedings of the Tenth ACM International Briefing on Web Search and Information Mining, Cambridge, United kingdom, half-dozen–x Feb 2017; pp. 485–494. [Google Scholar]
- Bao, Y.; Fang, H.; Zhang, J. Topicmf: Simultaneously exploiting ratings and reviews for recommendation. In Proceedings of the Twenty-Eighth AAAI Conference on Artificial Intelligence, Québec Urban center, QC, Canada, 27–31 July 2014; pp. 2–eight. [Google Scholar]
- Diao, Q.; Qiu, M.; Wu, C.; Smola, A.J.; Jiang, J.; Wang, C. Jointly modeling aspects, ratings and sentiments for picture recommendation (JMARS). In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August 2014; pp. 193–202. [Google Scholar]
- Jakob, N.; Weber, S.H.; Müller, Grand.C.; Gurevych, I. Beyond the stars: Exploiting free-text user reviews to improve the accuracy of movie recommendations. In Proceedings of the 1st International CIKM Workshop on Topic-Sentiment Analysis for Mass Stance, Hong Kong, Mainland china, 2–half-dozen November 2009; pp. 57–64. [Google Scholar]
- Gong, Fifty.; Al Boni, Chiliad.; Wang, H. Modeling social norms evolution for personalized sentiment classification. In Proceedings of the 54th Almanac Meeting of the Association for Computational Linguistics (Volume ane: Long Papers), Berlin, Germany, 7–12 August 2016; pp. 855–865. [Google Scholar]
- Gao, W.; Yoshinaga, N.; Kaji, N.; Kitsuregawa, One thousand. Modeling user leniency and product popularity for sentiment classification. In Proceedings of the 6th International Joint Conference on Natural Language Processing, Nagoya, Japan, xiv–18 October 2013; pp. 1107–1111. [Google Scholar]
Figure 1. Impacts of Number of Reviews Per User on MAE of Our Methods in Yelp2013 Datasets.
Figure 1. Impacts of Number of Reviews Per User on MAE of Our Methods in Yelp2013 Datasets.
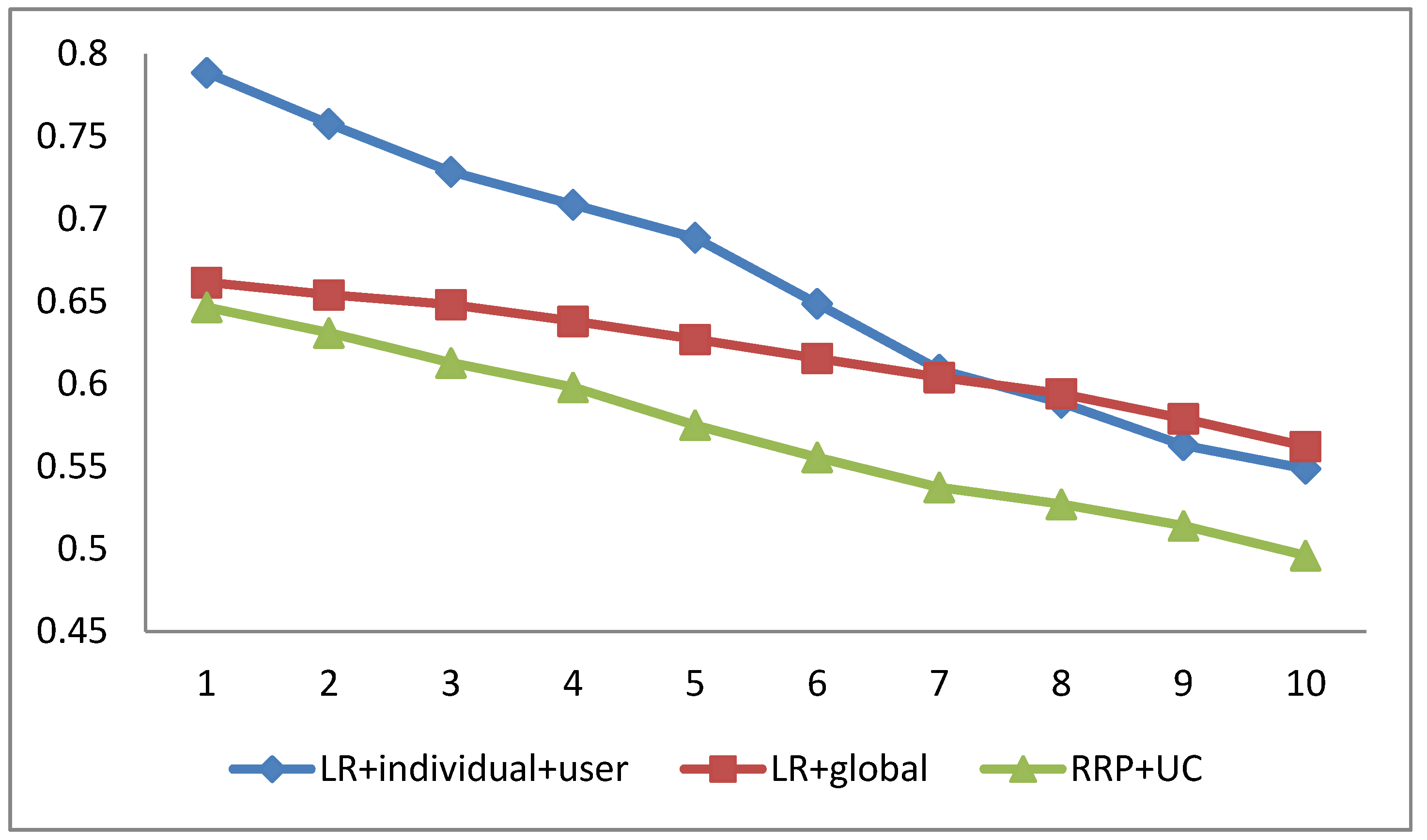
Figure 2. Impacts of Number of Reviews Per User on MAE of Our Methods in Yelp2013 Datasets.
Figure two. Impacts of Number of Reviews Per User on MAE of Our Methods in Yelp2013 Datasets.
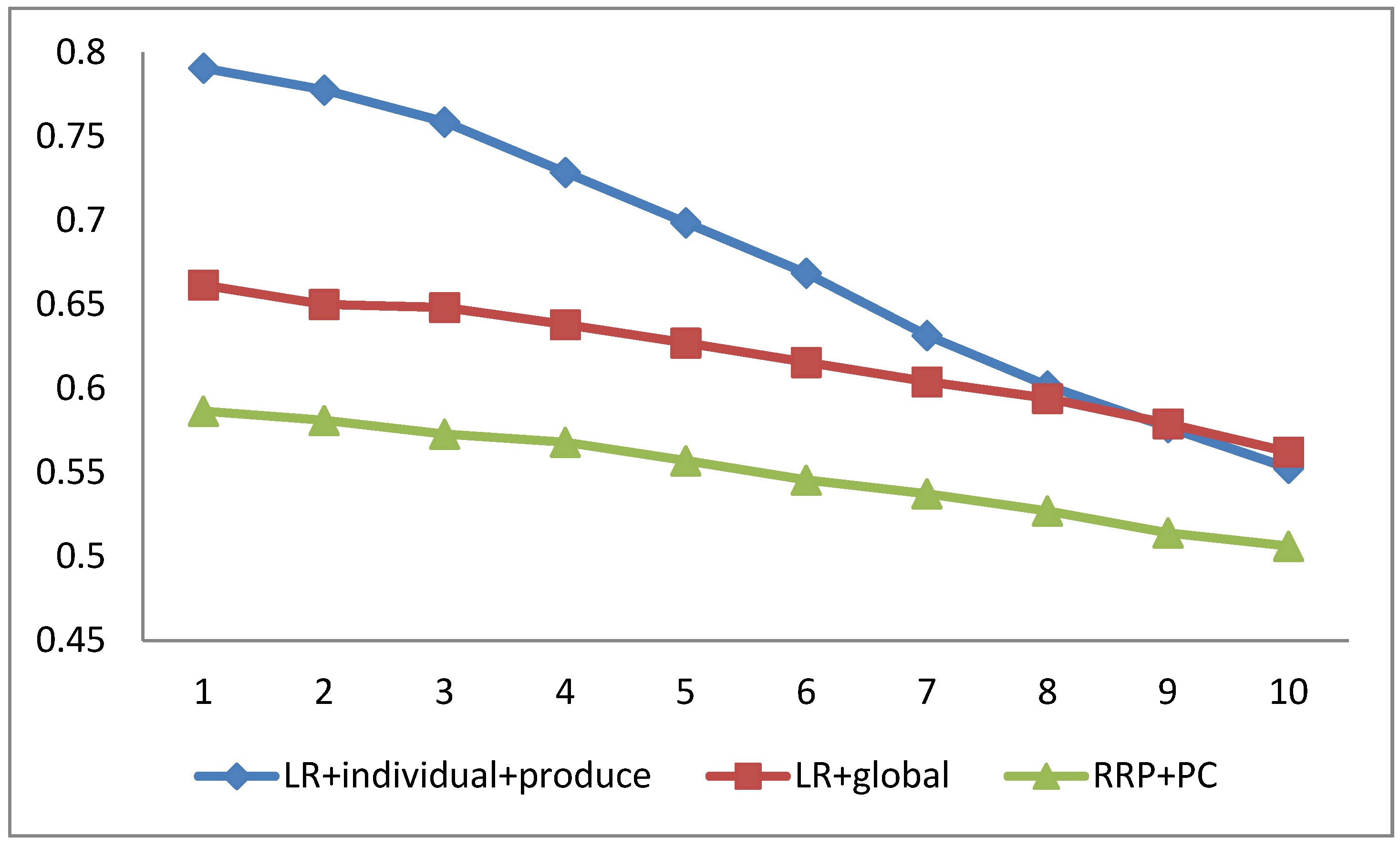
Figure 3. Impacts of User Context and Product Context on MAE of Our Methods in the Four Datasets.
Figure three. Impacts of User Context and Product Context on MAE of Our Methods in the Four Datasets.
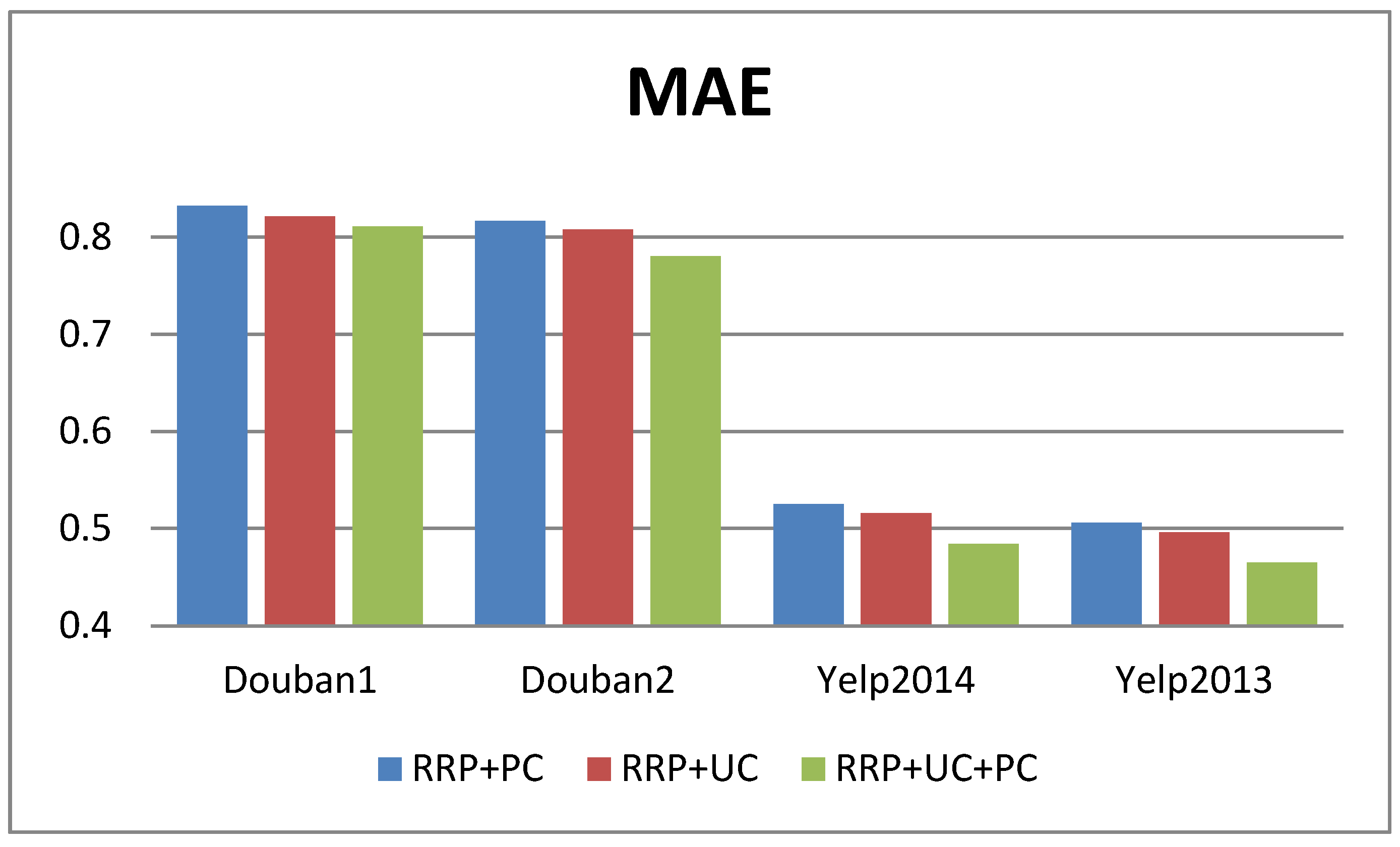
Figure four. Impacts of User Context and Product Context on RMSE of Our Methods in the Four Datasets.
Figure 4. Impacts of User Context and Product Context on RMSE of Our Methods in the Four Datasets.
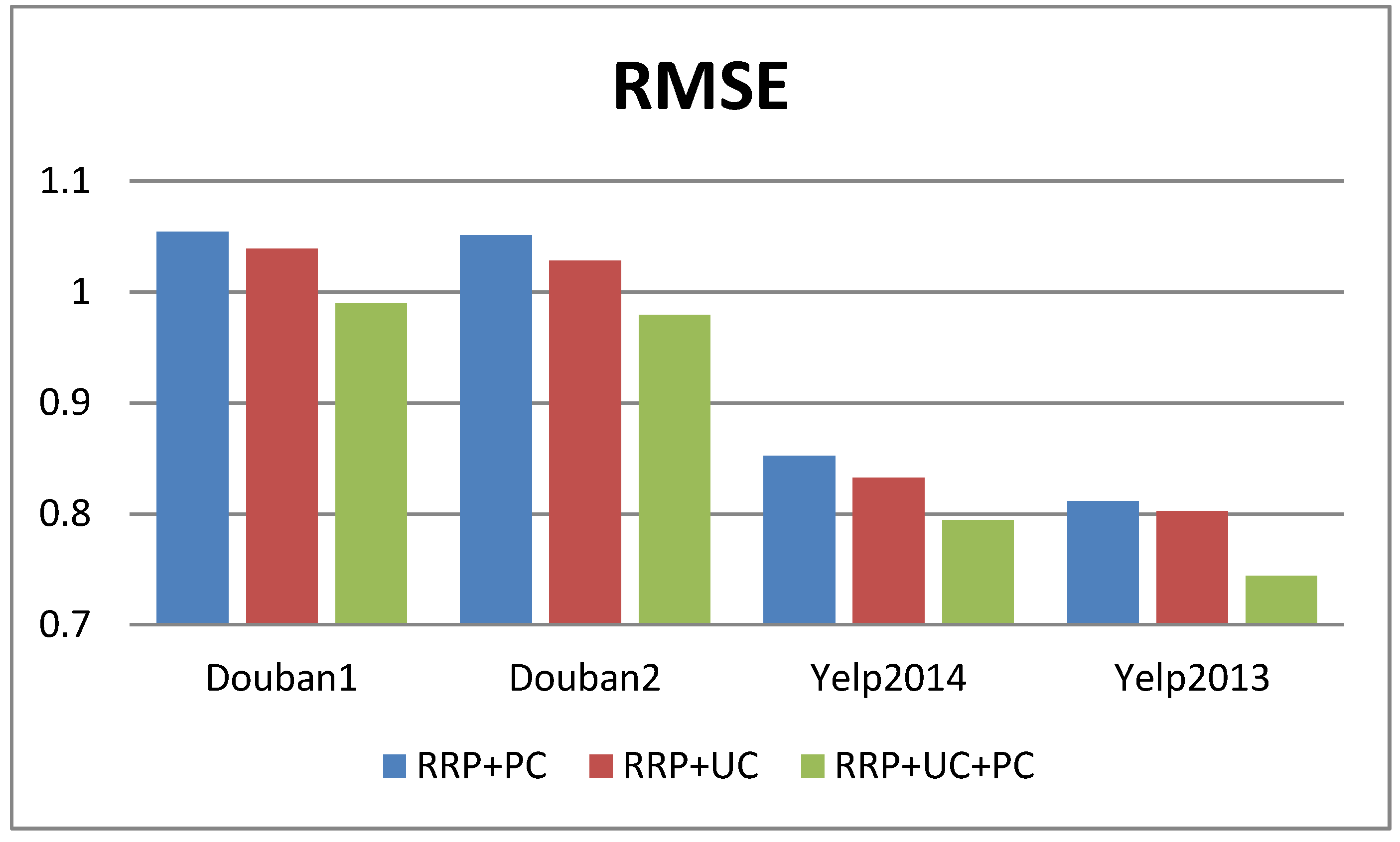
Table 1. Statistical Information of Yelp 2014, Yelp 2013, and 2 Douban Moving-picture show Review Datasets.
Table 1. Statistical Information of Yelp 2014, Yelp 2013, and Two Douban Picture show Review Datasets.
| Datasets | #Users | #Reviews | #Items | #Reviews/User | #Reviews/Product |
|---|---|---|---|---|---|
| Douban 1 | 1476 | 22,593 | 3041 | 15.31 | 7.43 |
| Douban ii | 1079 | 13,858 | 2087 | 12.84 | half-dozen.64 |
| Yelp 2014 | 4818 | 231,163 | 4194 | 47.97 | 55.12 |
| Yelp 2013 | 1631 | 78,966 | 1633 | 48.42 | 48.36 |
Tabular array 2. Mean accented error (MAE) and root hateful square mistake (RMSE) of Six Different Methods in 4 Datasets.
Table ii. Mean absolute mistake (MAE) and root mean foursquare error (RMSE) of Six Unlike Methods in 4 Datasets.
| Datasets | Douban1 | Douban1 | Douban2 | Douban2 | Yelp2014 | Yelp2014 | Yelp2013 | Yelp2013 |
|---|---|---|---|---|---|---|---|---|
| Metric | MAE | RMSE | MAE | RMSE | MAE | RMSE | MAE | RMSE |
| KNN | i.0659 | i.4547 | i.0626 | 1.4271 | 0.7112 | 0.9993 | 0.6987 | 0.9856 |
| MF | 0.8341 | 1.0653 | 0.8056 | 1.0387 | 0.5132 | 0.8146 | 0.4871 | 0.8042 |
| LR + global | 0.8477 | i.1008 | 0.8277 | one.0741 | 0.5686 | 0.8985 | 0.5623 | 0.8931 |
| LR + global + UPF | 0.8365 | 1.0681 | 0.8154 | one.0684 | 0.5305 | 0.8606 | 0.5225 | 0.8334 |
| LR + individual+product | 0.8431 | one.0909 | 0.8231 | 1.0702 | 0.5589 | 0.8884 | 0.5526 | 0.8736 |
| LR + individual + use | 0.8370 | 1.0703 | 0.8124 | ane.0645 | 0.5383 | 0.8682 | 0.5324 | 0.8533 |
| RRP + PC | 0.8325 | 1.0542 | 0.8170 | 1.0513 | 0.5252 | 0.8523 | 0.5062 | 0.8114 |
| RRP + UC | 0.8216 | i.0391 | 0.8081 | ane.0282 | 0.5158 | 0.8326 | 0.4961 | 0.8024 |
| RRP + RC + PC | 0.8111 | 0.9899 | 0.7803 | 0.9794 | 0.4841 | 0.7946 | 0.4652 | 0.7441 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This commodity is an open up access commodity distributed under the terms and weather of the Creative Commons Attribution (CC By) license (http://creativecommons.org/licenses/past/4.0/).
whitfeldparsettern67.blogspot.com
Source: https://www.mdpi.com/2076-3417/8/10/1849/htm